Audiotext reached 100 stars!

A few days ago, Audiotext reached the 100 stars milestone, which is my second project to achieve so, the first one being iOS Interview Questions. I realized that I hadn't written about Audiotext on this blog, so I thought it would be an appropriate moment to review the development of the project and how I plan to expand it.
Audiotext's trajectory
I started developing Audiotext in February 2023 as a side project to tinker with the Tkinter library for building GUIs in Python, as well as to try out localization in said language, which turned out to be quite similar to how it's done in C. I started using only the Google Speech-to-Text API, which was okay-ish because it was easy to implement for a fun little project. However, the generated transcriptions were poor, and I felt that the overall program had potential to become something bigger and better.
I think this screenshot of the first release can represent what I felt at the time:
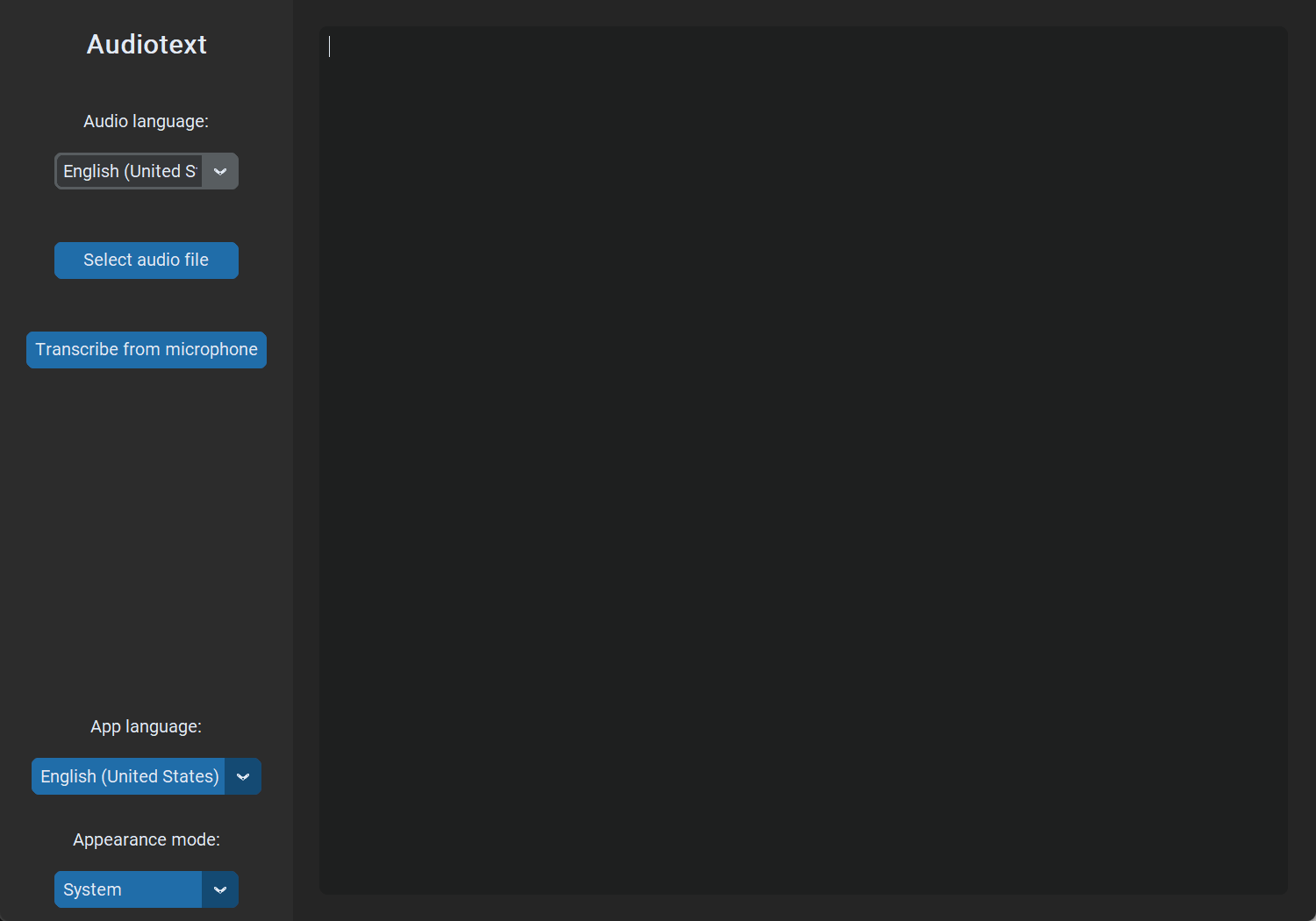
One of my main goals from that point on was to improve the UI, which was lacking in both features and visual appeal, and to implement WhisperX, a refined version of OpenAI's Whisper. I ended up doing both with the release of v2.0.0 on December 9, 2023. I had to remove the language option because some people reported problems starting the program due to the system's locale detection. I intended to remove it temporarily in order to fix it at some point in the future, but I haven't added it yet because I don't see any particular benefit to doing so, as the program is already pretty straightforward from a language perspective. However, I don't rule out reimplementing it at some point in the future.
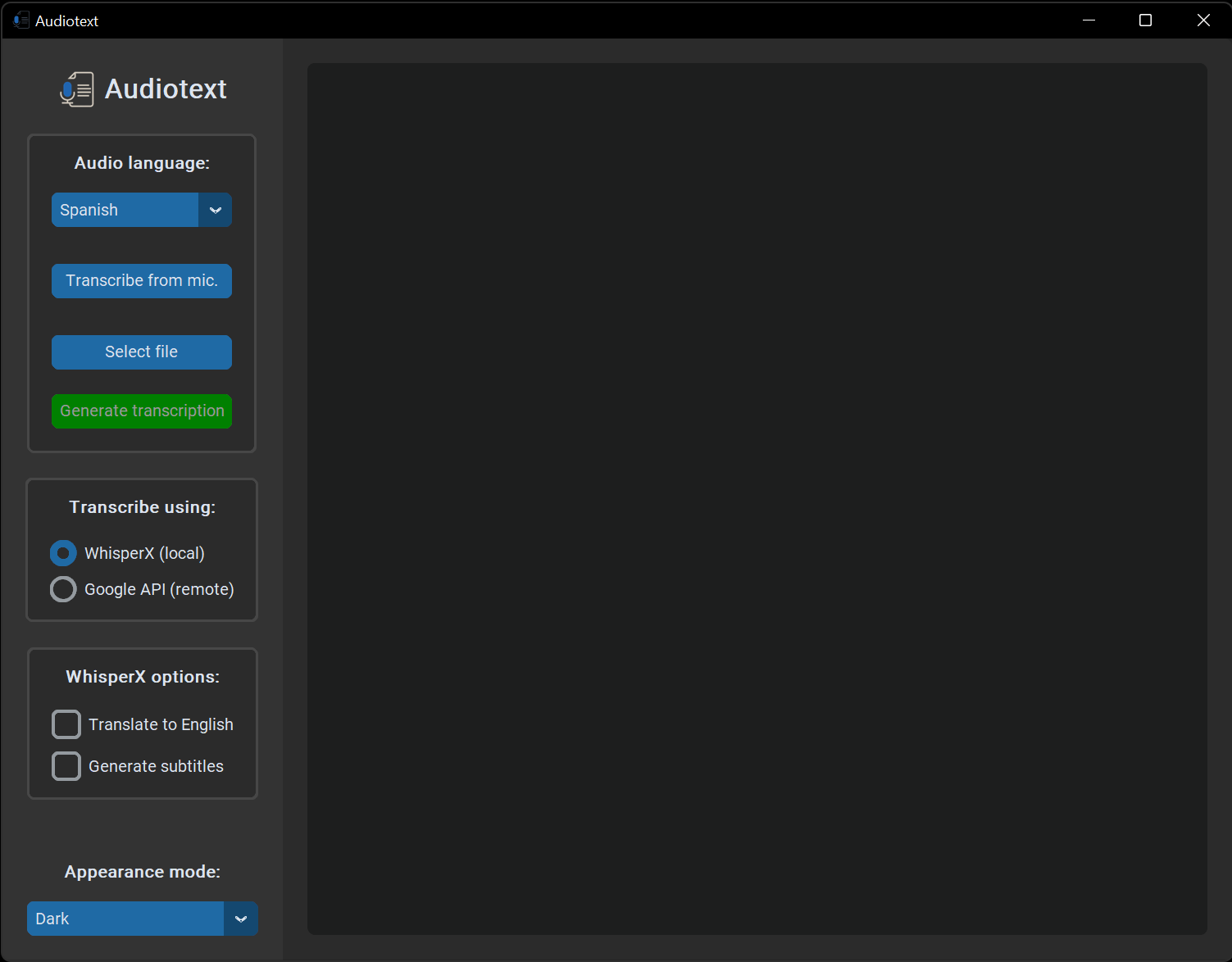
Three days after the v2.0.0 release, v2.1.0 was shipped. It included both subtitle options and advanced options for the WhisperX transcription method, which I had left out of v2.0.0 because I wanted to see if everything worked fine with the base WhisperX implementation. I also added the ability to persist the user configuration to avoid tweaking it every time the program starts.
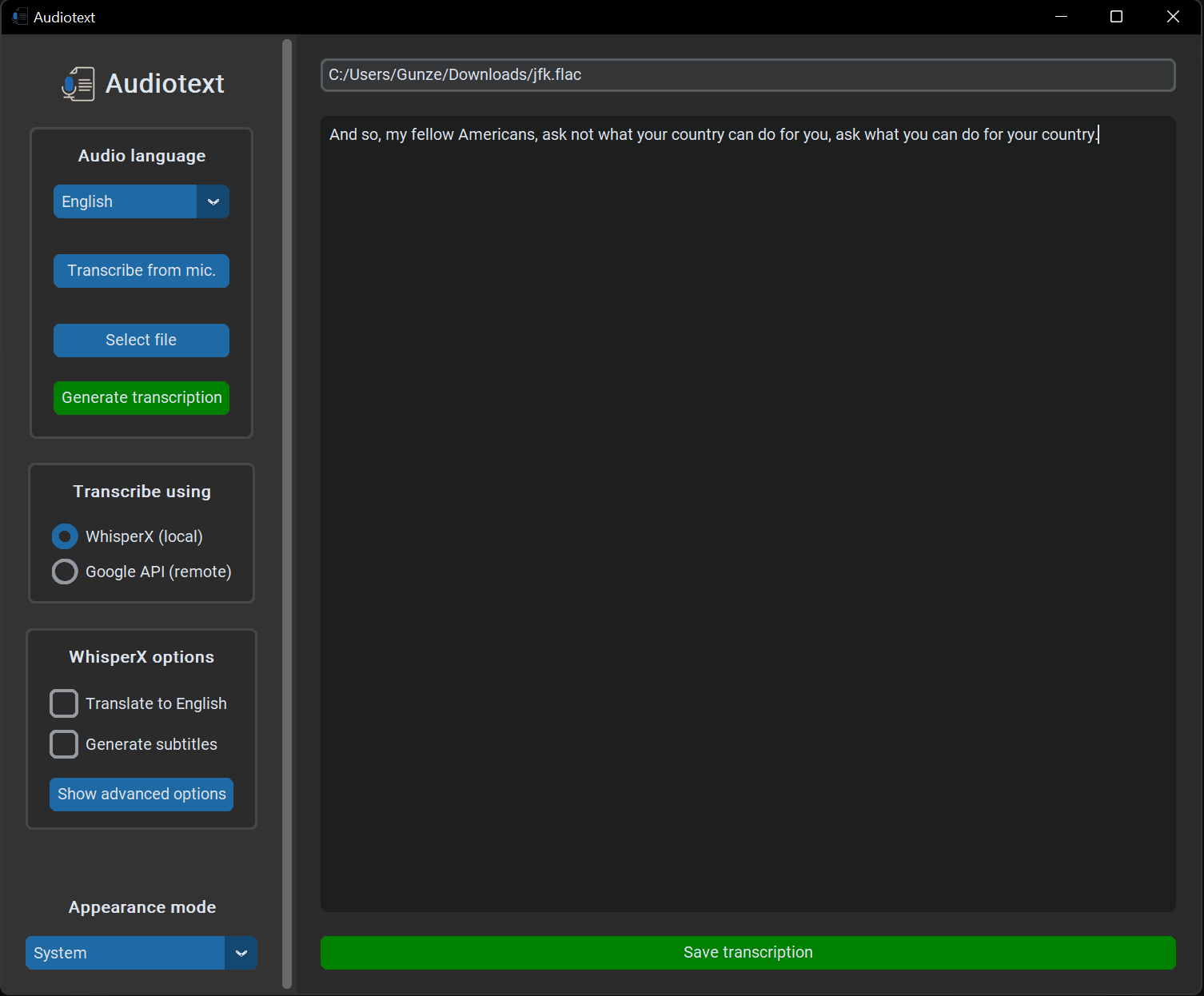
Five months later, on April 27, 2024, I released v2.2.0 with the option to transcribe YouTube videos, which was a feature that I added because I found myself in a situation where I needed to transcribe a video and thought that it would be a handy feature to have in Audiotext. I also tweaked the GUI and made it better organized by adding a combo box to select the source of the transcription and modifying the GUI accordingly.
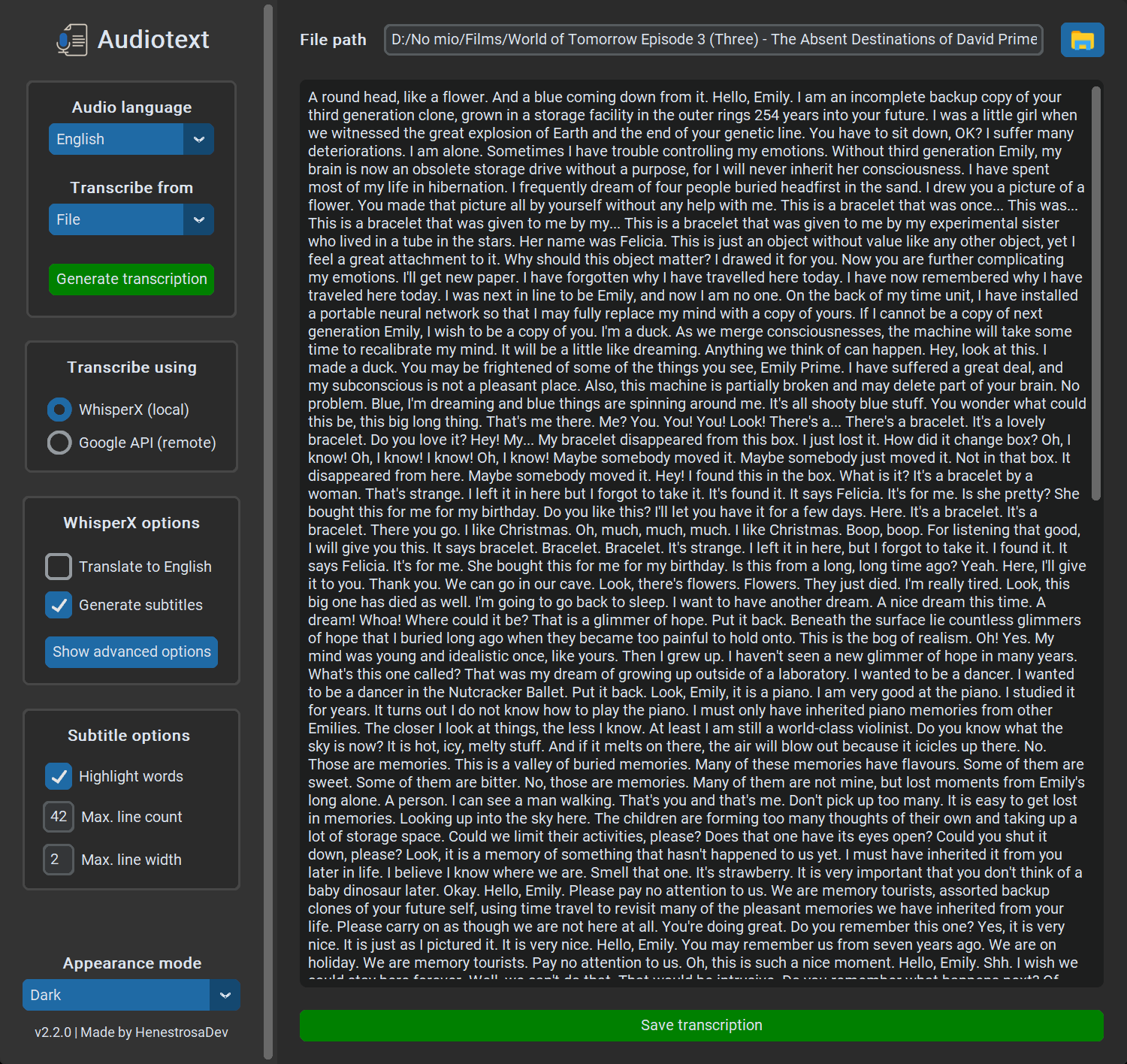
In v2.2.2, I added the option to autosave the generated transcription(s) and overwrite existing transcription files, as well as the option to transcribe the supported files in a directory. These additions improved the UX by giving more control over the way the transcriptions are saved and avoiding the need to transcribe multiple files one at a time.
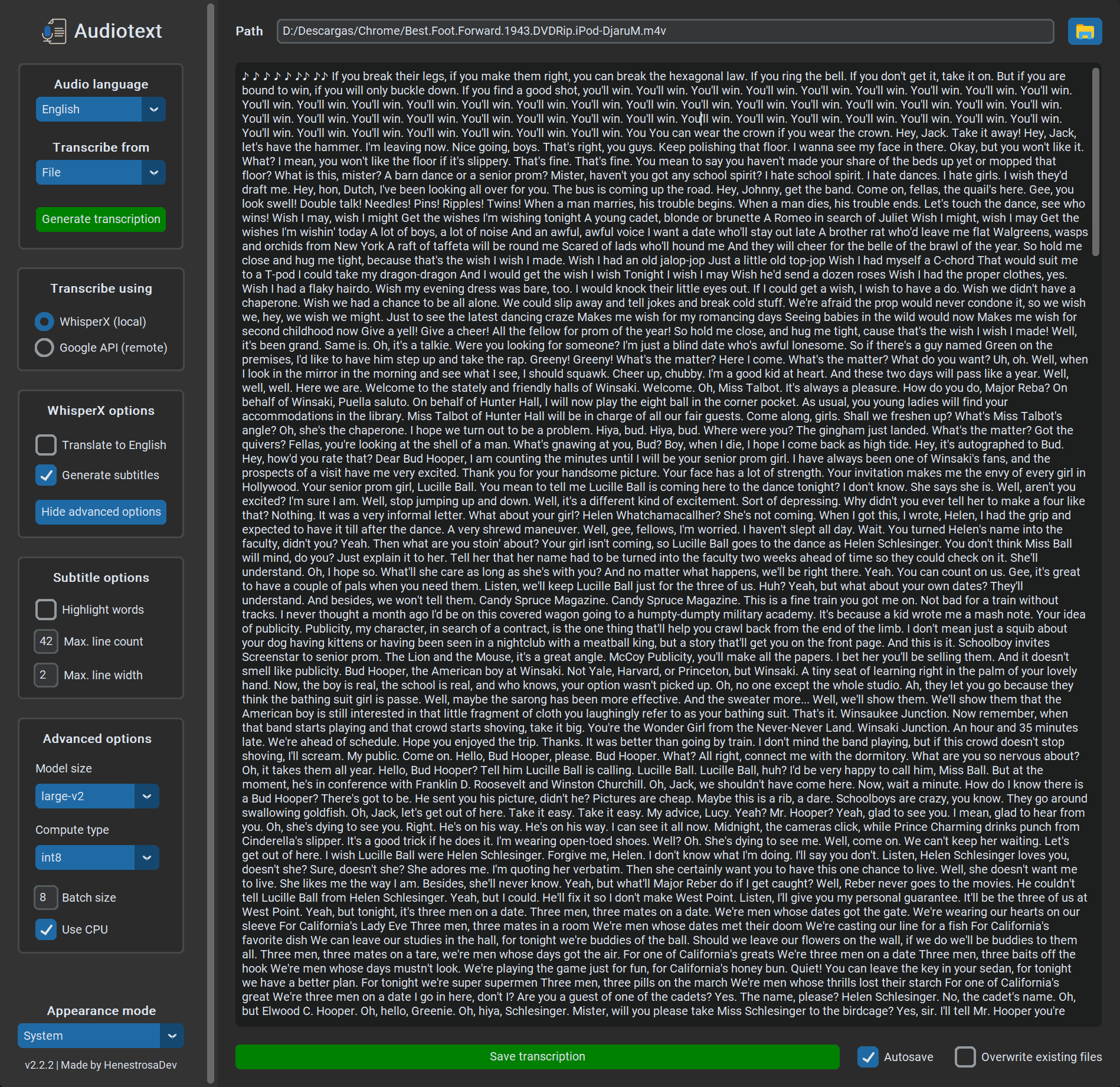
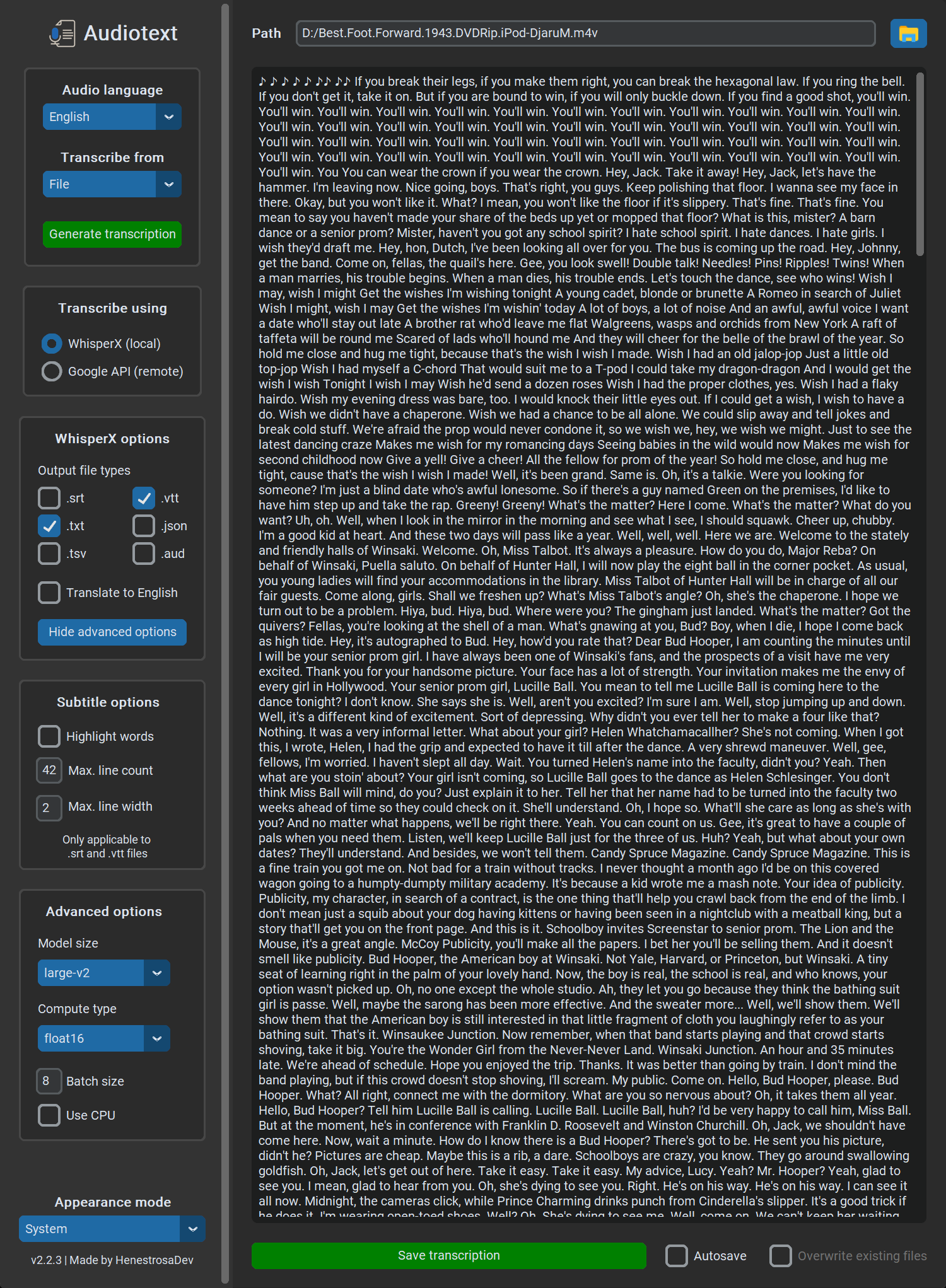
Finally, we come to the current release, which is v2.2.3, published on June 9th. It adds the output file types option to the WhisperX options, along with persistance of the selected appearance mode.
What's next?
While I'm pretty happy with the current state of the project, there are still a few things left to do, as noted in the Roadmap. I'd like to add the ability to abort an initialized transcription process, but doing this in Python is quite tricky because of the way the language handles threading. Similarly, I haven't been able to generate an .app executable for macOS, which will take some time, but is not as difficult to handle as the threading problem.
I'm sure there are more ways to improve Audiotext that I'll hopefully think of and implement in the future. However, if you have an idea that can improve the program, I'd be more than happy to read your suggestion in the discussions!